
Somewhere out there a user is about to open Invoice_FINAL_v3.xlsm, and the only thing standing between them and a ransom note is a mail filter that actually bothered to look inside the attachment. That .xlsm hides its VBA source inside a compressed OLE2 file, which is itself tucked inside a ZIP container. A raw scan sees packed bytes and shrugs. The dangerous part is in there, wearing three coats, a fake moustache, and the confident smile of someone who has done this before.
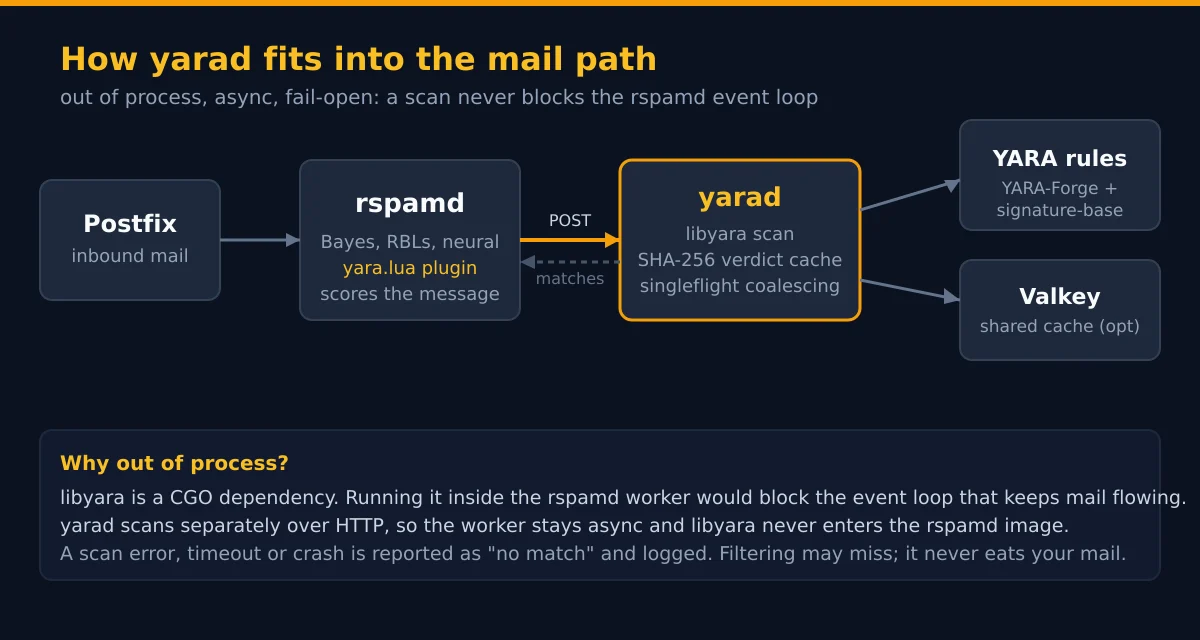
Rspamd is very good at deciding what a message is: spam, phishing, bulk noise, a forged sender, or a message whose links smell like a resignation letter waiting to happen. It is also built to ask outside services questions without stalling its workers, which is more than can be said for most software, or most users. YARA malware scanning in Rspamd slots into that design as an attachment-focused evidence stream: it takes hostile files apart until detection logic can see the bits that matter.
Mailstrix is the small scanner doing the dismantling. It is open source on GitHub and ships as a container on Docker Hub. Rspamd hands it a message or attachment over asynchronous HTTP; Mailstrix unwraps the containers, recovers the useful text and payloads, runs YARA, and returns evidence Rspamd can score. The mail worker never blocks waiting for it. That is the entire point, and the reason your queue does not back up every time someone emails a 40 MB spreadsheet of cat photos.
A macro is not a text file
Old Word and Excel files such as .doc and .xls use Microsoft’s Compound File Binary Format, mercifully shortened to OLE2. Picture a tiny filesystem crammed into a single file: named streams, storage directories, eldritch sector chains, and several decades of forensic trauma. A macro project lives in those streams, and its source is stored in the MS-OVBA compression format, because of course it is.
Modern .docm and .xlsm files dress better. They are ZIP archives stuffed with XML. The macro project is still an OLE2 file, usually vbaProject.bin, buried in the archive like a body in a basement. So a rule hunting for AutoOpen, WScript.Shell, or a dodgy URL will sail straight past a raw compressed macro and find nothing. This is not YARA failing. This is YARA being shown a locked box and asked to describe the contents.
Mailstrix magic-sniffs the attachment, opens the OLE2 or OOXML, locates the VBA streams, decompresses them, and scans the recovered source as a separate buffer. It scans the original file too, because format-level exploits live there. For the extracted source it sets YARA’s VBA external variable, so macro rules can be precise instead of treating every newsletter that contains the word “Shell” as the opening scene of a heist film.
What suspicious VBA actually looks like
A macro running when a document opens is not, by itself, proof of malice. Plenty of finance departments still run workbooks that resemble an archaeological dig with a quarterly budget. But a macro that auto-runs, writes a file to disk, and launches it has stopped being an annoying spreadsheet and become a line item in next week’s incident report.
Document_Open
+ ADODB.Stream or SaveToFile
+ WScript.Shell, ShellExecute, or PowerShell
= a very bad Tuesday for someone who is not youThe local Maldoc_AutoExec_Write_Execute rule demands all three categories at once. That restraint is deliberate. A lone CreateObject is normal in half the macros ever written. A lone AutoOpen is everywhere. But an auto-execution trigger plus a file-drop primitive plus an execute primitive in the same buffer is a real signal, and it lets Rspamd add a score that means something instead of crying wolf at every monthly sales report.
Malicious VBA loves hiding its strings in pieces, like a ransom note assembled from magazine cuttings. It builds commands with Chr() and ChrW(), shuffles characters through Replace(), reverses literals with StrReverse(), XORs byte arrays, and occasionally trots out the Dridex-style string encoding that has been irritating analysts since roughly 2015. Mailstrix folds those common forms back into readable text and scans the result again. A URL chopped into twenty innocent-looking fragments is still a URL once you scrape the glue off.
One limit, stated bluntly so nobody files a bug about it later: this is static analysis. Mailstrix does not run the macro, click through Office’s “are you really sure” prompts, or emulate an entire Excel workbook while your SMTP queue taps its foot. It applies bounded decoding and structural checks. The deep, genuinely cursed end of VBA analysis still belongs to oletools and the parallel Olefy scanner. Two tools, one mail stream, zero faith in attachments.
The Office tricks that skip the macro entirely
Some document attacks do not bother embedding a macro at all, because why work harder than the victim. An OOXML relationship can point Word or Excel at a remote template or OLE object. That is the remote-template-injection family: a clean-looking document politely asks Office to go fetch someone else’s content the moment it opens. Mailstrix reads the _rels/*.rels parts and surfaces remote http, https, SMB, and UNC targets to a dedicated rule. The attachment looks empty because, in the attacker’s preferred version of events, the interesting part is still in transit.
DDE and DDEAUTO fields are another ancient problem that refuses to lie down and die quietly. A field instruction can convince Office to ask another program to do work on its behalf. Mailstrix pulls these instructions from OOXML document, header, and footer XML, including the split text runs that try to hide the letters “DDE” from anyone searching lazily. It recognises the same idea in RTF, SYLK, CSV, and Excel 2003 XML. Formula injection is not exotic when a spreadsheet cell starts with =, +, -, or @; DDE is just the version where someone showed up with a crowbar and a grudge.
Excel 4.0 macros, usually called XLM, earn their own pile of suspicion. They predate VBA and live in macro sheets that can be hidden, or “very hidden”, which is Microsoft’s way of admitting the first hidden wasn’t sincere. A workbook can carry no visible VBA project at all while an XLM sheet fires off a command through a formula language older than some of your colleagues. Mailstrix identifies macrosheets in both OOXML and legacy BIFF workbooks, reads the dangerous formula forms, and resolves a bounded set of simple cell references. It does not pretend to be a full Excel interpreter. That particular ambition has eaten better-funded projects whole.
Then there is VBA stomping, the trick for people who read the detection docs and got ideas. A document can carry compiled VBA p-code that Office happily executes while the visible source is empty or harmless. Mailstrix compares “substantial p-code present” against “implausibly tiny decompressed source” and raises a VBA-STOMPED marker. It is a heuristic, not a p-code disassembler. That distinction stays boring right up until someone treats a score as a verdict and quarantines the chief accountant’s beloved 2004 workbook. Then it becomes your distinction to explain, slowly, in a meeting.
The attachment zoo is much larger than Office
RTF is the format people call harmless approximately four seconds before it hands them a hexadecimal object blob. Mailstrix decodes {\*\objdata ...}, follows the embedded OLE packages, and feeds each extracted child straight back through the same dispatcher. An RTF object can therefore unfold into a PDF, a script, or yet another Office document, each parsed in turn under one shared size-and-depth budget. The budget is not optional. Skip it and an email attachment becomes a small, well-dressed decompression bomb, and the only thing it detonates is your free time.
PDF gets the same suspicion rather than blind trust, because PDF has earned every ounce of it. Mailstrix inflates Flate streams and flags the actions that travel with trouble: JavaScript wired to /OpenAction, /Launch, additional actions, embedded files, deliberately obfuscated names, and the historic /JBIG2Decode exploit path. A PDF has no business behaving like a program loader. The PDF specification disagrees, at length, which is how we got here.
The less glamorous routes are also the more common ones, because attackers are nothing if not practical: Outlook .msg files with nested attachments, OneNote .one files, Windows .lnk shortcuts carrying command lines, MSI payloads, VBE and JSE encoded scripts, OLE Package streams such as Ole10Native, and the full ZIP / 7z / RAR / gzip / tar family. Every carved child returns to the same format detector. A PDF inside a message attachment inside a ZIP does not get a hall pass just because the attacker had patience and you, briefly, did not.
YARA malware scanning in Rspamd starts with evidence
Only after Mailstrix has produced clean, useful buffers does ordinary YARA matching get to do its best work. The service loads roughly 10,000 curated public rules alongside local checks for document behaviour. Those rules see raw files, decoded macro source, extracted objects, and recovered scripts. They also get the attachment filename and extension, which matters enormously for rules expecting a lure named invoice.pdf.exe by someone who genuinely believed nobody would notice the second extension. Someone always notices. Mailstrix notices for a living. The upstream rule sources are credited and pinned in the project’s README; this post is about the evidence those rules finally get handed.
That rule set is a starting point, not a divine oracle. A hit might name a malware family, a known exploit pattern, a phishing kit, or a broad heuristic. Mailstrix returns the rule name, its tags, and the source namespace; the Rspamd plugin sorts those into score tiers, with strong family and exploit hits ranked above low-confidence indicators. Start every deployment at score 0.0, read the logs for a while, and tune the noisy rules before you let them reject anything. Detection-only mode is not cowardice. It is how you avoid discovering, at 09:04 on a Monday, that payroll was your test corpus and the CFO is on line one.
Three optional abuse.ch feeds add evidence from outside the rule corpus. URLhaus checks URLs found in the message and extracted content, including the usual defanged disguises such as hxxp and [.]. MalwareBazaar checks an attachment’s SHA-256 against known malware. ThreatFox adds URL and domain IOCs from active campaigns. All three are cached locally and fail open. A feed outage should cost you a little detection coverage, never a delivered message. Losing mail because a third party had a bad afternoon is how trust in a filter dies.
Rspamd is still the brain; Mailstrix is the crowbar
Mailstrix does not try to replace Rspamd’s judgement — it pries open the attachment so that judgement has something to read.
Rspamd already fuses authentication results, URL reputation, fuzzy hashes, Bayes, neural classification, and its own rules into one mail decision. The wider tour lives in Rspamd explained. Attachment archaeology is a heavy, specialised job that sits beside that decision, so the Lua plugin fires an asynchronous request at Mailstrix instead of dragging libyara and a zoo of parsers into the worker process where they can take everything down with them.
The separation buys real operational peace. A botched rule reload leaves the previous compiled bundle running, so a bad edit cannot disarm a live scanner. A scan timeout, a parse error, or an honest-to-goodness libyara panic reports “no match” and logs the failure instead of dropping the message. Verdicts are cached by SHA-256, and concurrent copies of the same campaign coalesce into a single scan. Your CPU did not consent to inspect the same poisoned invoice 500 times just because the sender blind-copied the entire org chart.
You can run the Rspamd path at SMTP time for scoring, or use the small strix-scan client from Dovecot Sieve at delivery time to quarantine matches after the obvious junk has already been rejected. The first reacts sooner; the second lifts expensive analysis off the connection-critical path. Your mail flow decides which is right. There is no trophy for making the fastest SMTP conversation also do the most work, and anyone who tells you otherwise has never had to explain a timeout to a sales team.
The whole thing is open source at github.com/myguard-labs/mailstrix, with extractor tests and the rule build included, and the ready-to-run image lives on Docker Hub. The current release is v1.1.0, with static amd64 and arm64 binaries and .deb packages on the release page for anyone who would rather not run a container. The full project tour, deployment paths, and FAQ live at mailstrix.com. Treat the score as another set of eyes, keep Office patched, and stay permanently suspicious of Q2_forecast_FINAL_FINAL.xlsm. That filename has never, in the entire history of email, brought good news.
Frequently asked questions
Does Rspamd have built-in YARA scanning?
No. Rspamd has a strong asynchronous plugin model but no native YARA module. A small Lua plugin sends messages and attachments to an out-of-process YARA scanner such as Mailstrix, then turns the returned evidence into ordinary Rspamd symbols and scores.
Why must a scanner decompress Office VBA macros?
The source in an old OLE2 document, or in the vbaProject.bin inside a DOCM or XLSM, is MS-OVBA-compressed. A raw scan only sees packed bytes, so macro keywords and URLs are invisible. Decompressing the VBA gives YARA and behavioural rules the actual text to inspect.
What is VBA stomping?
VBA stomping is a document trick where compiled p-code stays present but the visible VBA source is empty or misleading. Office can still execute the p-code. Mailstrix flags the suspicious mismatch as a heuristic; it does not disassemble the p-code or claim to prove malware from that signal alone.
Can YARA scanning catch macro-free Office attacks?
Yes. Mailstrix looks for external OOXML relationships, DDE and DDEAUTO fields, hidden XLM macrosheets, OLE2Link URL monikers, and suspicious embedded objects. Those techniques can fetch or execute content without any obvious VBA project in the document.
Which attachments besides Office documents are inspected?
Mailstrix handles RTF object data, PDF streams and actions, Outlook MSG attachments, OneNote files, LNK shortcuts, encoded scripts, MSI and OLE package payloads, and nested ZIP, 7z, RAR, gzip, and tar archives. Each extracted child is scanned again within strict depth and byte limits.
Will a YARA scanner block mail when it fails?
It should not. Mailstrix fails open on timeouts, parse errors, rule problems, and backend failures. Rspamd records whatever evidence it receives, and a scanner outage becomes an observability problem rather than a reason to lose a legitimate message.
Related reading
- Olefy and Rspamd: scan Office macro malware in your mail. The Python and oletools companion for deeper macro analysis.
- Rspamd explained: how modern spam filtering actually works. The mail-filtering layers that attachment evidence joins.
- DCC, Razor and Pyzor for Rspamd: one Docker backend. Another out-of-process service pattern for a busy Rspamd install.
- Docker hardening for self-hosters. The rootless, read-only, distroless posture used for scanner containers.
Mailstrix does not execute VBA, so deeply multi-stage droppers that need full olevba deobfuscation or dynamic unpacking are best left running alongside. Many stacks run Mailstrix as the drop-in and keep olevba only as a parallel scorer for that long tail — see mailstrix.com for the full picture.